Dans cet article, nous allons mettre en place un pipeline GitHub Actions permettant de déployer automatiquement une infrastructure Azure à l’aide d’OpenTofu. L’objectif est de montrer comment industrialiser le provisioning de ressources cloud, en adoptant une approche Infrastructure as Code (IaC) reproductible, versionnée et totalement automatisée.
Cette approche me permet aussi d’approvisionner rapidement des environnements de test et de les détruire tout aussi facilement, ce qui contribue à mieux maîtriser les coûts.
OpenTofu en bref
OpenTofu est un fork open source de Terraform, créé suite au changement de licence de Terraform vers BUSL 1.1 (Business Source License). Cette licence n’étant plus considérée comme open source, OpenTofu propose une alternative 100 % ouverte, tout en restant compatible avec la syntaxe et les providers Terraform. Cela signifie que les utilisateurs peuvent migrer leurs configurations existantes sans effort, tout en conservant les mêmes workflows et outils.
Le projet OpenTofu est accessible ici
Qu'est-ce que GitHub Actions
GitHub Actions est la plateforme CI/CD intégrée à GitHub. Elle permet d’automatiser des workflows. Dans ce contexte, elle servira simplement à exécuter OpenTofu afin de déployer notre infrastructure Azure de manière automatisée et reproductible.
Pour plus d’informations, consultez la page officielle de github
Exemple d'Infrastructure Azure à déployer
Dans notre exemple, nous partons sur une architecture classique autour d’Azure Databricks pour construire des pipelines ETL batch et streaming avec Delta Lake.
Cette architecture sera composée d’un Azure Data Factory pour l’ingestion orchestrée, d’un Azure Event Hubs pour les flux temps réel, d’un compte Azure Data Lake Storage Gen2 pour le stockage des données en différentes zones, et d’un workspace Azure Databricks pour les transformations batch et streaming.

Concrètement, les ressources à créer seront :
- Un Resource Group
- Un compte Storage ADLS Gen2
- Un Event Hub
- Un Azure Data Factory
- Un workspace Azure Databricks
- Un Azure Key Vault pour centraliser les secrets
Ces ressources seront déployées sur plusieurs environnements (dev, int, uat et prd) afin de simuler un cas réaliste et de pouvoir tester des déploiements applicatifs de bout en bout.
Pour une description plus complète de cette architecture, vous pouvez consulter la documentation Microsoft.

Pour faciliter le suivi, la reprise et la destruction des déploiements, un backend OpenTofu sera utilisé et hébergé dans Azure.
Autoriser Github action dans Azure
Pour permettre à GitHub Actions de déployer notre infrastructure, nous configurons l’authentification OIDC entre GitHub et Azure. Azure AD émettra alors un jeton d’accès éphémère pour chaque workflow. Techniquement, cela consiste à créer une Federated Credential sur le service principal, liée au repository et au workflow GitHub. Une fois en place, les pipelines peuvent s’authentifier sans secret statique et exécuter directement les commandes OpenTofu ou Azure CLI.
Commencez par créer une application enregistrée dans Microsoft Entra ID, qui servira de service principal pour l’authentification OIDC depuis GitHub Actions.
az ad app create --display-name "sqlyotta-github-oidc"Notez l’appId retourné ; nous l’utiliserons plus loin sous l’identifiant <APP_ID>.
Créez également un service principal associé à cet <APP_ID>.
az ad sp create --id "<APP_ID>"
Attribuez le rôle Owner au niveau de la souscription (dans notre cas, un environnement de test). En production, un rôle Contributor appliqué au niveau du Resource Group est généralement suffisant.
az role assignment create \
--assignee <APP_ID> \
--role "Owner" \
--scope "/subscriptions/<SUBSCRIPTION_ID>"
Ajoutez maintenant une Federated Credential. C’est l’élément central du mécanisme OIDC entre GitHub et Azure. À chaque exécution d’un workflow, GitHub émet un jeton OIDC incluant des claims tels que le repository, la branche et l’environnement (si défini dans GitHub Actions). Azure utilisera ces claims pour valider l’identité du workflow et délivrer un jeton d’accès éphémère au service principal.
# DEV
az ad app federated-credential create \
--id "<APP_ID>" \
--parameters '{
"name": "github-oidc-dev-credential",
"issuer": "https://token.actions.githubusercontent.com",
"subject": "repo:<OWNER>/<REPO>:environment:dev",
"audiences": ["api://AzureADTokenExchange"]
}'
# INT
az ad app federated-credential create \
--id "<APP_ID>" \
--parameters '{
"name": "github-oidc-int-credential",
"issuer": "https://token.actions.githubusercontent.com",
"subject": "repo:<OWNER>/<REPO>:environment:int",
"audiences": ["api://AzureADTokenExchange"]
}'
# UAT
az ad app federated-credential create \
--id "<APP_ID>" \
--parameters '{
"name": "github-oidc-uat-credential",
"issuer": "https://token.actions.githubusercontent.com",
"subject": "repo:<OWNER>/<REPO>:environment:uat",
"audiences": ["api://AzureADTokenExchange"]
}'
# PRD
az ad app federated-credential create \
--id "<APP_ID>" \
--parameters '{
"name": "github-oidc-prd-credential",
"issuer": "https://token.actions.githubusercontent.com",
"subject": "repo:<OWNER>/<REPO>:environment:prd",
"audiences": ["api://AzureADTokenExchange"]
}'
Création d’un Storage Account destiné au backend OpenTofu.
# Variables
LOCATION="francecentral"
RG_NAME="rg-iac-state"
STO_NAME="stsqlyottaiacstate"
CONTAINER_NAME="tfstate"
# Resource group
az group create \
--name "$RG_NAME" \
--location "$LOCATION"
# Storage Account
az storage account create \
--name "$STO_NAME" \
--resource-group "$RG_NAME" \
--location "$LOCATION" \
--sku Standard_LRS \
--kind StorageV2
# Container pour les tfstate
az storage container create \
--name "$CONTAINER_NAME" \
--account-name "$STO_NAME"
Récupérer l’ID du Storage Account.
STO_ID=$(az storage account show \
--name stsqlyottaiacstate \
--resource-group rg-iac-state \
--query "id" -o tsv)Attribuer le rôle Storage Blob Data Contributor.
az role assignment create \
--assignee <APP_ID> \
--role "Storage Blob Data Contributor" \
--scope "$STO_ID"
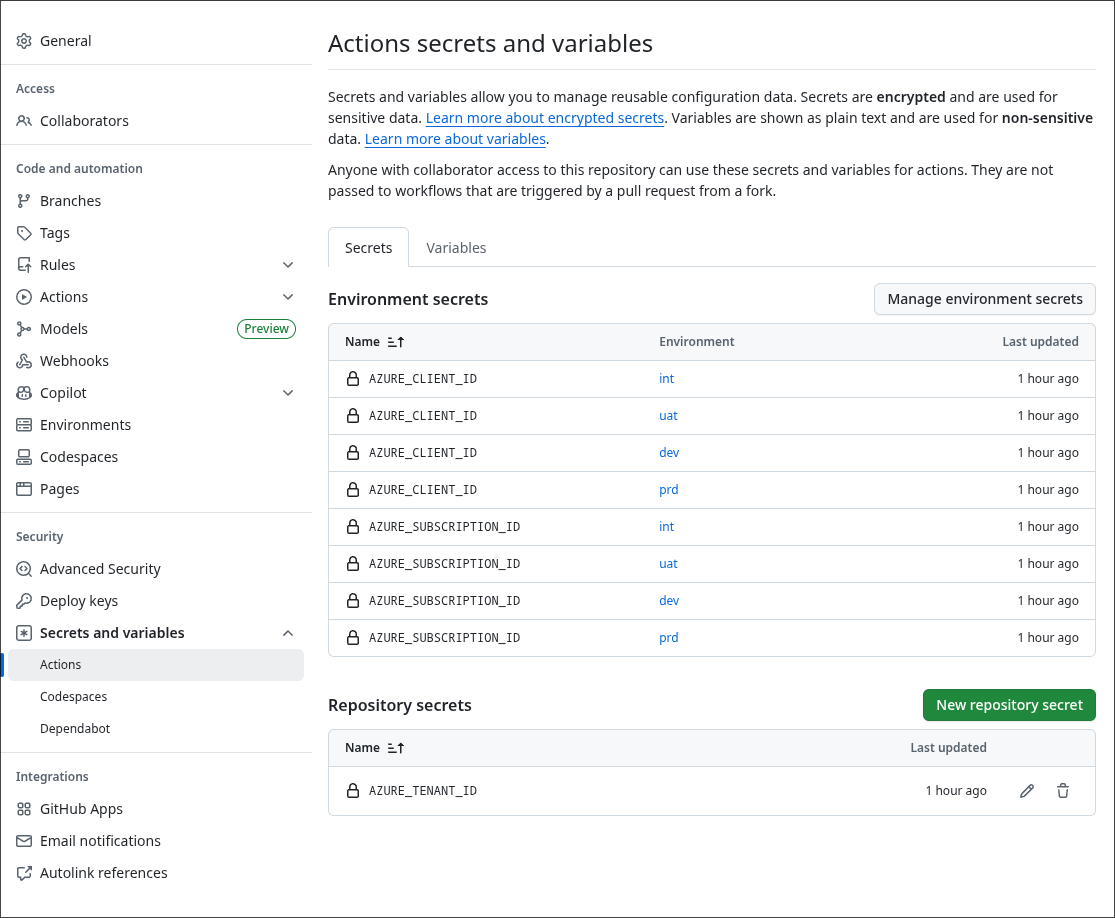
Création des secrets dans Github
Dans GitHub, créez les secrets nécessaires pour accéder à l’environnement de test. Notez que certains secrets sont définis au niveau du repository et d’autres au niveau des environnements GitHub Actions, afin de refléter une pratique courante où chaque environnement (dev, int, uat, prd) peut correspondre à une souscription Azure distincte.
Tester la connexion entre GitHub Actions et Azure
À l’aide d’un workflow minimal, nous allons valider la connectivité et les permissions entre GitHub Actions et Azure.
Créez la structure suivante dans votre repository GitHub :
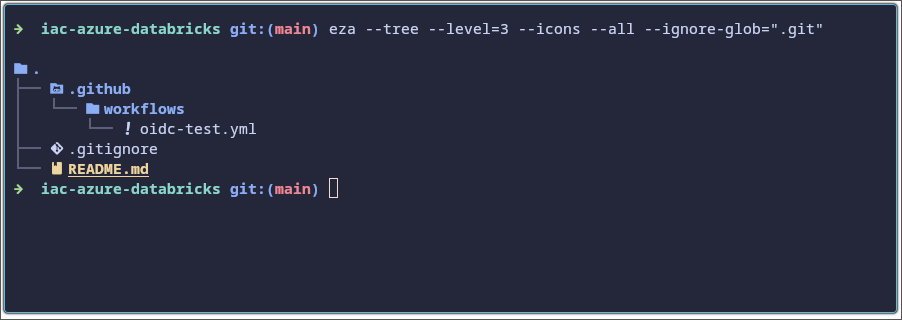
Ci-dessous, le contenu du fichier oidc-test.yml.
name: Test Azure OIDC Connection
on:
workflow_dispatch:
permissions:
id-token: write
contents: read
jobs:
test-azure-oidc:
runs-on: ubuntu-latest
environment: dev
steps:
- name: Checkout repository
uses: actions/checkout@v4
- name: Login to Azure using OIDC
uses: azure/login@v2
with:
client-id: ${{ secrets.AZURE_CLIENT_ID }}
tenant-id: ${{ secrets.AZURE_TENANT_ID }}
subscription-id: ${{ secrets.AZURE_SUBSCRIPTION_ID }}
- name: Show Azure account
run: |
echo "== az account show =="
az account show
- name: List resource groups
run: |
echo "== az group list =="
az group list --query "[].{name:name, location:location}" -o table
- name: List storage accounts
run: |
echo "== az storage account list =="
az storage account list --query "[].{name:name, rg:resourceGroup}" -o tableLancez le workflow afin de confirmer que la connectivité est opérationnelle.
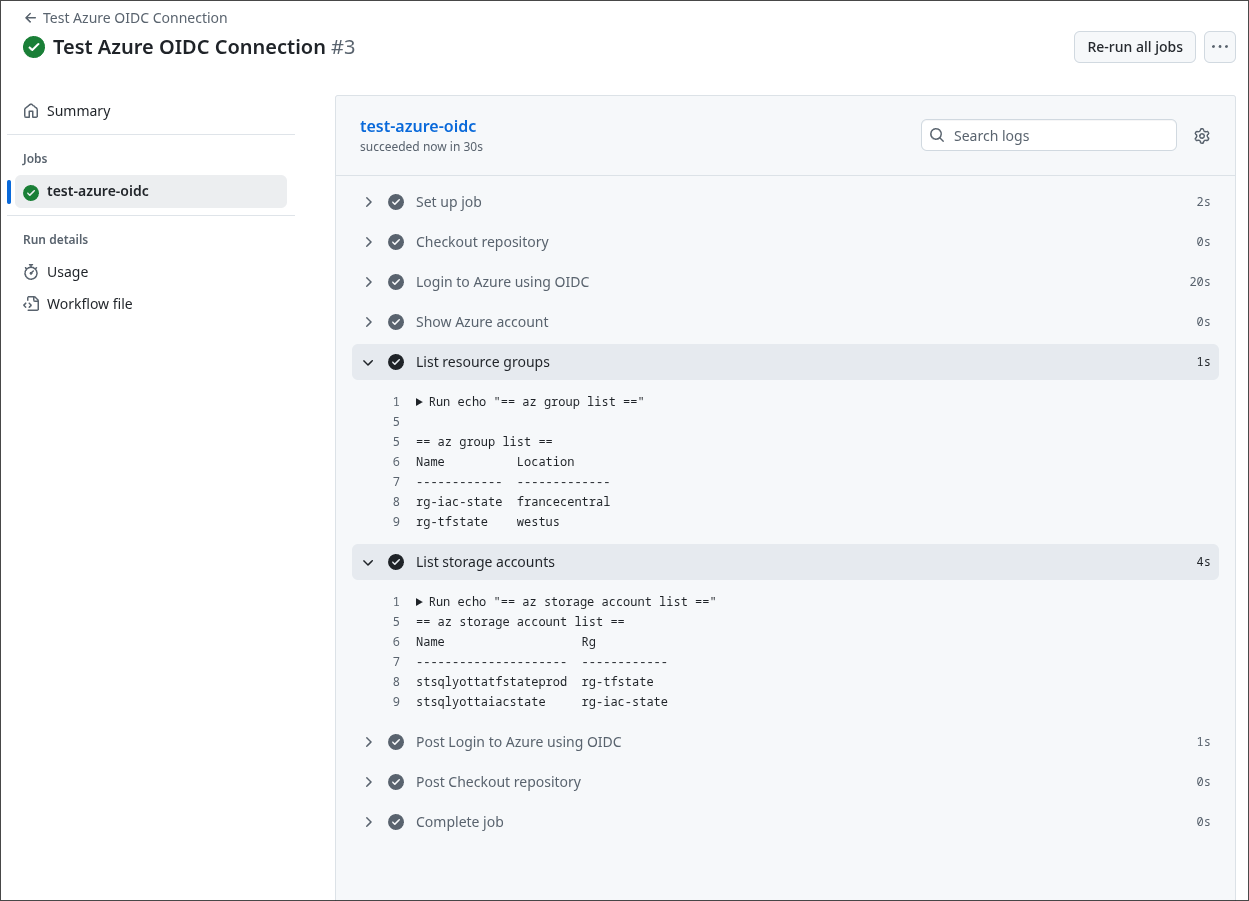
Comme vous pouvez le constater, le workflow s’exécute avec succès et parvient à lister les Resource Groups ainsi que les comptes de stockage, dont celui destiné à héberger le backend OpenTofu (créé précédemment).
Définition de l’infrastructure (OpenTofu / Terraform)
Cette section présente l’ensemble des fichiers OpenTofu utilisés pour définir et déployer l’infrastructure Azure. On y retrouve la configuration du backend, les providers, les variables, ainsi que les ressources nécessaires pour provisionner Data Factory, Event Hubs, Databricks, le Data Lake et les composants IAM associés.
Chaque environnement (dev, int, uat, prd) dispose également de ses propres fichiers .tfvars pour isoler la configuration et permettre des déploiements indépendants.
infra/opentofu/backend.tf
Ce fichier configure le backend distant OpenTofu/Terraform dans Azure Storage. Il définit le Resource Group, le Storage Account, le container et la clé où sera stocké l’état (tfstate).
terraform {
backend "azurerm" {
resource_group_name = "rg-iac-state"
storage_account_name = "stsqlyottaiacstate"
container_name = "tfstate"
key = "placeholder.tfstate"
}
}infra/opentofu/main.tf
Ce fichier décrit le cœur de l’infrastructure : Resource Group, compte ADLS Gen2, Data Lake filesystem, Event Hub , Key Vault, Data Factory, Databricks workspace et les rôles IAM associés.
########################################
# Locals
########################################
locals {
env_suffix = lower(var.environment)
rg_name = "rg-${var.project_prefix}-${local.env_suffix}"
storage_name = "st${var.project_prefix}${local.env_suffix}" # doit être unique globalement
kv_name = "kv-${var.project_prefix}-${local.env_suffix}"
adf_name = "adf-${var.project_prefix}-${local.env_suffix}"
databricks_name = "dbw-${var.project_prefix}-${local.env_suffix}"
datalake_fs = "datalake"
eventhub_ns_name = "evhns-${var.project_prefix}-${local.env_suffix}"
eventhub_name = "evh-${var.project_prefix}-${local.env_suffix}"
}
data "azurerm_client_config" "current" {}
########################################
# 1. Resource Group
########################################
resource "azurerm_resource_group" "rg" {
name = local.rg_name
location = var.location
}
########################################
# 2. Storage Account (Data Lake Gen2)
########################################
resource "azurerm_storage_account" "datalake" {
name = local.storage_name
resource_group_name = azurerm_resource_group.rg.name
location = azurerm_resource_group.rg.location
account_tier = "Standard"
account_replication_type = "LRS"
account_kind = "StorageV2"
# Data Lake Gen2
is_hns_enabled = true
}
resource "azurerm_storage_data_lake_gen2_filesystem" "fs" {
name = local.datalake_fs
storage_account_id = azurerm_storage_account.datalake.id
}
# Conteneur pour la capture Event Hub (raw events)
resource "azurerm_storage_container" "eventhub_capture" {
name = "raw-eventhub"
storage_account_id = azurerm_storage_account.datalake.id
container_access_type = "private"
}
########################################
# 3. Key Vault
########################################
resource "azurerm_key_vault" "kv" {
name = local.kv_name
location = azurerm_resource_group.rg.location
resource_group_name = azurerm_resource_group.rg.name
tenant_id = data.azurerm_client_config.current.tenant_id
sku_name = "standard"
soft_delete_retention_days = 7
purge_protection_enabled = false
# Accès pour l'utilisateur courant (toi)
access_policy {
tenant_id = data.azurerm_client_config.current.tenant_id
object_id = data.azurerm_client_config.current.object_id
secret_permissions = [
"Get",
"List",
"Set",
"Delete"
]
}
tags = {
environment = var.environment
project = var.project_prefix
}
}
########################################
# 4. Data Factory
########################################
resource "azurerm_data_factory" "adf" {
name = local.adf_name
location = azurerm_resource_group.rg.location
resource_group_name = azurerm_resource_group.rg.name
identity {
type = "SystemAssigned"
}
tags = {
environment = var.environment
project = var.project_prefix
}
}
########################################
# 5. IAM : ADF → Storage
########################################
data "azurerm_role_definition" "storage_blob_data_contributor" {
name = "Storage Blob Data Contributor"
scope = azurerm_storage_account.datalake.id
}
resource "azurerm_role_assignment" "adf_to_datalake" {
scope = azurerm_storage_account.datalake.id
role_definition_id = data.azurerm_role_definition.storage_blob_data_contributor.id
principal_id = azurerm_data_factory.adf.identity[0].principal_id
}
########################################
# 6. IAM : ADF → Key Vault
########################################
resource "azurerm_key_vault_access_policy" "adf_kv_policy" {
key_vault_id = azurerm_key_vault.kv.id
tenant_id = data.azurerm_client_config.current.tenant_id
object_id = azurerm_data_factory.adf.identity[0].principal_id
secret_permissions = [
"Get",
"List"
]
}
########################################
# 7. Databricks Workspace
########################################
resource "azurerm_databricks_workspace" "dbw" {
name = local.databricks_name
resource_group_name = azurerm_resource_group.rg.name
location = azurerm_resource_group.rg.location
# Standard / Premium / Trial
sku = "standard"
# RG managé créé automatiquement par Databricks
managed_resource_group_name = "rg-${var.project_prefix}-${local.env_suffix}-dbw-managed"
tags = {
environment = var.environment
project = var.project_prefix
}
}
########################################
# 9. Azure Event Hubs
########################################
resource "azurerm_eventhub_namespace" "eh_ns" {
name = local.eventhub_ns_name
location = azurerm_resource_group.rg.location
resource_group_name = azurerm_resource_group.rg.name
sku = "Standard"
capacity = 1
tags = {
environment = var.environment
project = var.project_prefix
}
}
resource "azurerm_eventhub" "eh" {
name = local.eventhub_name
namespace_name = azurerm_eventhub_namespace.eh_ns.name
resource_group_name = azurerm_resource_group.rg.name
partition_count = 4
message_retention = 1 # jours
capture_description {
enabled = true
encoding = "Avro"
interval_in_seconds = 300
size_limit_in_bytes = 10485760
destination {
name = "EventHubArchive.AzureBlockBlob"
storage_account_id = azurerm_storage_account.datalake.id
blob_container_name = azurerm_storage_container.eventhub_capture.name
archive_name_format = "{Namespace}/{EventHub}/{PartitionId}/{Year}/{Month}/{Day}/{Hour}/{Minute}/{Second}"
}
}
}
resource "azurerm_eventhub_namespace_authorization_rule" "eh_ns_sas" {
name = "sas-adf-or-apps"
namespace_name = azurerm_eventhub_namespace.eh_ns.name
resource_group_name = azurerm_resource_group.rg.name
listen = true
send = true
manage = false
}
resource "azurerm_key_vault_secret" "eh_connection_string" {
name = "eventhub-connection-string"
value = azurerm_eventhub_namespace_authorization_rule.eh_ns_sas.primary_connection_string
key_vault_id = azurerm_key_vault.kv.id
}infra/opentofu/providers.tf
Ce fichier déclare les providers nécessaires : azurerm pour les ressources Azure et azuread pour l’identité (Entra ID). C’est ici que l’on active les fonctionnalités du provider Azure.
provider "azurerm" {
features {}
resource_provider_registrations = "none"
}
provider "azuread" {}infra/opentofu/variables.tf
Ce fichier centralise les variables partagées : préfixe de projet, environnement et région. Les différents environnements (dev/int/uat/prd) surchargent ces valeurs via leurs fichiers .tfvars.
variable "project_prefix" {
type = string
default = "sqlyotta"
}
variable "environment" {
type = string
}
variable "location" {
type = string
default = "francecentral"
}infra/opentofu/envs/dev.tfvars (int/uat/prd)
Les fichiers .tfvars définissent les valeurs spécifiques à chaque environnement (nom logique, région, etc.). Ils permettent de réutiliser le même code main.tf pour dev, int, uat et prd simplement en changeant le fichier de variables passé à OpenTofu.
environment = "dev"
location = "westus"Workflows GitHub Actions
Cette section présente les workflows GitHub Actions utilisés pour automatiser le déploiement de l’infrastructure Azure.
.github/workflows/opentofu-pipeline.yml
Ce workflow GitHub Actions orchestre le déploiement multi-environnements de l’infrastructure OpenTofu. Il exécute successivement les stages DEV, INT, UAT et PROD, chacun utilisant son fichier .tfvars et son backend d’état dédié. À chaque étape, le pipeline s’authentifie via OIDC, initialise le backend, puis applique la configuration OpenTofu de manière automatisée.
name: "OpenTofu Multi-Stage Pipeline (Databricks)"
on:
workflow_dispatch:
permissions:
id-token: write
contents: read
env:
TF_WORKING_DIR: infra/opentofu
jobs:
# -------------------------------
# STAGE 1 : DEV
# -------------------------------
deploy_dev:
name: "Deploy DEV"
runs-on: ubuntu-latest
environment: dev
env:
ARM_USE_OIDC: true
ARM_CLIENT_ID: ${{ secrets.AZURE_CLIENT_ID }}
ARM_TENANT_ID: ${{ secrets.AZURE_TENANT_ID }}
ARM_SUBSCRIPTION_ID: ${{ secrets.AZURE_SUBSCRIPTION_ID }}
steps:
- uses: actions/checkout@v4
- name: Azure Login
uses: azure/login@v2
with:
client-id: ${{ secrets.AZURE_CLIENT_ID }}
tenant-id: ${{ secrets.AZURE_TENANT_ID }}
subscription-id: ${{ secrets.AZURE_SUBSCRIPTION_ID }}
- name: Install OpenTofu
uses: opentofu/setup-opentofu@v1
with:
tofu_version: "1.8.3"
- name: OpenTofu Init DEV
working-directory: ${{ env.TF_WORKING_DIR }}
run: |
tofu init \
-backend-config="key=lakehouse-dev.tfstate"
- name: OpenTofu Apply DEV (full)
working-directory: ${{ env.TF_WORKING_DIR }}
run: |
tofu apply \
-lock-timeout=5m \
-auto-approve \
-input=false \
-var-file="envs/dev.tfvars"
# -------------------------------
# STAGE 2 : INT
# -------------------------------
deploy_int:
name: "Deploy INT"
runs-on: ubuntu-latest
needs: deploy_dev
environment: int
env:
ARM_USE_OIDC: true
ARM_CLIENT_ID: ${{ secrets.AZURE_CLIENT_ID }}
ARM_TENANT_ID: ${{ secrets.AZURE_TENANT_ID }}
ARM_SUBSCRIPTION_ID: ${{ secrets.AZURE_SUBSCRIPTION_ID }}
steps:
- uses: actions/checkout@v4
- name: Azure Login
uses: azure/login@v2
with:
client-id: ${{ secrets.AZURE_CLIENT_ID }}
tenant-id: ${{ secrets.AZURE_TENANT_ID }}
subscription-id: ${{ secrets.AZURE_SUBSCRIPTION_ID }}
- name: Install OpenTofu
uses: opentofu/setup-opentofu@v1
with:
tofu_version: "1.8.3"
- name: OpenTofu Init INT
working-directory: ${{ env.TF_WORKING_DIR }}
run: |
tofu init \
-backend-config="key=lakehouse-int.tfstate"
- name: OpenTofu Apply INT (full)
working-directory: ${{ env.TF_WORKING_DIR }}
run: |
tofu apply \
-lock-timeout=5m \
-auto-approve \
-input=false \
-var-file="envs/int.tfvars"
# -------------------------------
# STAGE 3 : UAT
# -------------------------------
deploy_uat:
name: "Deploy UAT"
runs-on: ubuntu-latest
needs: deploy_int
environment: uat
env:
ARM_USE_OIDC: true
ARM_CLIENT_ID: ${{ secrets.AZURE_CLIENT_ID }}
ARM_TENANT_ID: ${{ secrets.AZURE_TENANT_ID }}
ARM_SUBSCRIPTION_ID: ${{ secrets.AZURE_SUBSCRIPTION_ID }}
steps:
- uses: actions/checkout@v4
- name: Azure Login
uses: azure/login@v2
with:
client-id: ${{ secrets.AZURE_CLIENT_ID }}
tenant-id: ${{ secrets.AZURE_TENANT_ID }}
subscription-id: ${{ secrets.AZURE_SUBSCRIPTION_ID }}
- name: Install OpenTofu
uses: opentofu/setup-opentofu@v1
with:
tofu_version: "1.8.3"
- name: OpenTofu Init UAT
working-directory: ${{ env.TF_WORKING_DIR }}
run: |
tofu init \
-backend-config="key=lakehouse-uat.tfstate"
- name: OpenTofu Apply UAT (full)
working-directory: ${{ env.TF_WORKING_DIR }}
run: |
tofu apply \
-lock-timeout=5m \
-auto-approve \
-input=false \
-var-file="envs/uat.tfvars"
# -------------------------------
# STAGE 4 : PROD
# -------------------------------
deploy_prd:
name: "Deploy PROD"
runs-on: ubuntu-latest
needs: deploy_uat
environment: prd
env:
ARM_USE_OIDC: true
ARM_CLIENT_ID: ${{ secrets.AZURE_CLIENT_ID }}
ARM_TENANT_ID: ${{ secrets.AZURE_TENANT_ID }}
ARM_SUBSCRIPTION_ID: ${{ secrets.AZURE_SUBSCRIPTION_ID }}
steps:
- uses: actions/checkout@v4
- name: Azure Login
uses: azure/login@v2
with:
client-id: ${{ secrets.AZURE_CLIENT_ID }}
tenant-id: ${{ secrets.AZURE_TENANT_ID }}
subscription-id: ${{ secrets.AZURE_SUBSCRIPTION_ID }}
- name: Install OpenTofu
uses: opentofu/setup-opentofu@v1
with:
tofu_version: "1.8.3"
- name: OpenTofu Init PROD
working-directory: ${{ env.TF_WORKING_DIR }}
run: |
tofu init \
-backend-config="key=lakehouse-prd.tfstate"
- name: OpenTofu Apply PROD (full)
working-directory: ${{ env.TF_WORKING_DIR }}
run: |
tofu apply \
-lock-timeout=5m \
-auto-approve \
-input=false \
-var-file="envs/prd.tfvars".github/workflows/opentofu-destroy.yml
Ce second workflow permet de détruire sélectivement un environnement OpenTofu. L’utilisateur choisit l’environnement à supprimer (dev, int, uat ou prd) lors du déclenchement manuel. Le pipeline s’authentifie via OIDC, initialise le backend associé à l’environnement, puis exécute un tofu destroy avec le fichier .tfvars correspondant.
name: "OpenTofu Destroy"
on:
workflow_dispatch:
inputs:
environment:
description: "Environment to destroy"
required: true
type: choice
options:
- dev
- int
- uat
- prd
permissions:
id-token: write
contents: read
env:
TF_WORKING_DIR: infra/opentofu
jobs:
destroy:
name: "Destroy environment"
runs-on: ubuntu-latest
environment: ${{ github.event.inputs.environment }}
env:
ARM_USE_OIDC: true
ARM_CLIENT_ID: ${{ secrets.AZURE_CLIENT_ID }}
ARM_TENANT_ID: ${{ secrets.AZURE_TENANT_ID }}
ARM_SUBSCRIPTION_ID: ${{ secrets.AZURE_SUBSCRIPTION_ID }}
steps:
- name: Checkout
uses: actions/checkout@v4
- name: Azure Login
uses: azure/login@v2
with:
client-id: ${{ secrets.AZURE_CLIENT_ID }}
tenant-id: ${{ secrets.AZURE_TENANT_ID }}
subscription-id: ${{ secrets.AZURE_SUBSCRIPTION_ID }}
- name: Install OpenTofu
uses: opentofu/setup-opentofu@v1
with:
tofu_version: "1.8.3" # ou "latest"
- name: OpenTofu Init
working-directory: ${{ env.TF_WORKING_DIR }}
run: |
tofu init \
-backend-config="key=lakehouse-${{ github.event.inputs.environment }}.tfstate"
- name: OpenTofu Destroy
working-directory: ${{ env.TF_WORKING_DIR }}
run: |
tofu destroy -auto-approve \
-input=false \
-var-file="envs/${{ github.event.inputs.environment }}.tfvars".github/workflows/opentofu-unlock.yml
Ce workflow sert à déverrouiller manuellement un fichier d’état OpenTofu lorsque celui-ci reste bloqué dans Azure Storage, par exemple après une exécution interrompue. L’utilisateur sélectionne l’environnement à débloquer, puis le pipeline s’authentifie via OIDC, identifie le blob correspondant au fichier tfstate et vérifie son état de verrouillage. Si un lease actif est détecté, il est automatiquement brisé via Azure CLI.
Ce mécanisme permet surtout de rétablir un état propre du backend et d’éviter les blocages lors des prochains déploiements.
name: "OpenTofu Unlock"
on:
workflow_dispatch:
inputs:
environment:
description: "Environment (dev, int, uat, prd)"
required: true
default: "dev"
type: choice
options:
- dev
- int
- uat
- prd
permissions:
id-token: write
contents: read
concurrency:
group: opentofu-unlock
cancel-in-progress: false
env:
TFSTATE_RG: rg-iac-state
TFSTATE_STORAGE: stsqlyottaiacstate
TFSTATE_CONTAINER: tfstate
jobs:
unlock:
runs-on: ubuntu-latest
environment: dev
steps:
- name: Checkout
uses: actions/checkout@v4
- name: Azure Login (OIDC)
uses: azure/login@v2
with:
client-id: ${{ secrets.AZURE_CLIENT_ID }}
tenant-id: ${{ secrets.AZURE_TENANT_ID }}
subscription-id: ${{ secrets.AZURE_SUBSCRIPTION_ID }}
- name: Compute tfstate blob name
id: tfstate
run: |
ENV="${{ github.event.inputs.environment }}"
echo "blob_name=lakehouse-${ENV}.tfstate" >> $GITHUB_OUTPUT
- name: Show current lease state
run: |
az storage blob show \
--account-name $TFSTATE_STORAGE \
--container-name $TFSTATE_CONTAINER \
--name "${{ steps.tfstate.outputs.blob_name }}" \
--auth-mode login \
--query "properties.lease"
- name: Break lease if locked
run: |
STATUS=$(az storage blob show \
--account-name $TFSTATE_STORAGE \
--container-name $TFSTATE_CONTAINER \
--name "${{ steps.tfstate.outputs.blob_name }}" \
--auth-mode login \
--query "properties.lease.status" -o tsv || echo "none")
if [ "$STATUS" = "locked" ]; then
echo "Lease locked, breaking..."
az storage blob lease break \
--account-name $TFSTATE_STORAGE \
--container-name $TFSTATE_CONTAINER \
--blob-name "${{ steps.tfstate.outputs.blob_name }}" \
--auth-mode login
else
echo "No active lock (status=$STATUS)"
fi
- name: Check lease after break
run: |
az storage blob show \
--account-name $TFSTATE_STORAGE \
--container-name $TFSTATE_CONTAINER \
--name "${{ steps.tfstate.outputs.blob_name }}" \
--auth-mode login \
--query "properties.lease"Exécution du workflow
Pour lancer un workflow GitHub Actions, il suffit d’aller dans l’onglet Actions du repository, de sélectionner le workflow souhaité, puis de cliquer sur Run workflow. GitHub permet de choisir la branche ou les paramètres d’entrée définis dans le workflow.
Nous commençons par lancer le workflow chargé de créer l’infrastructure Azure. Celui-ci initialise le backend, s’authentifie via OIDC, puis déploie les ressources définies dans le code OpenTofu pour l’environnement sélectionné.
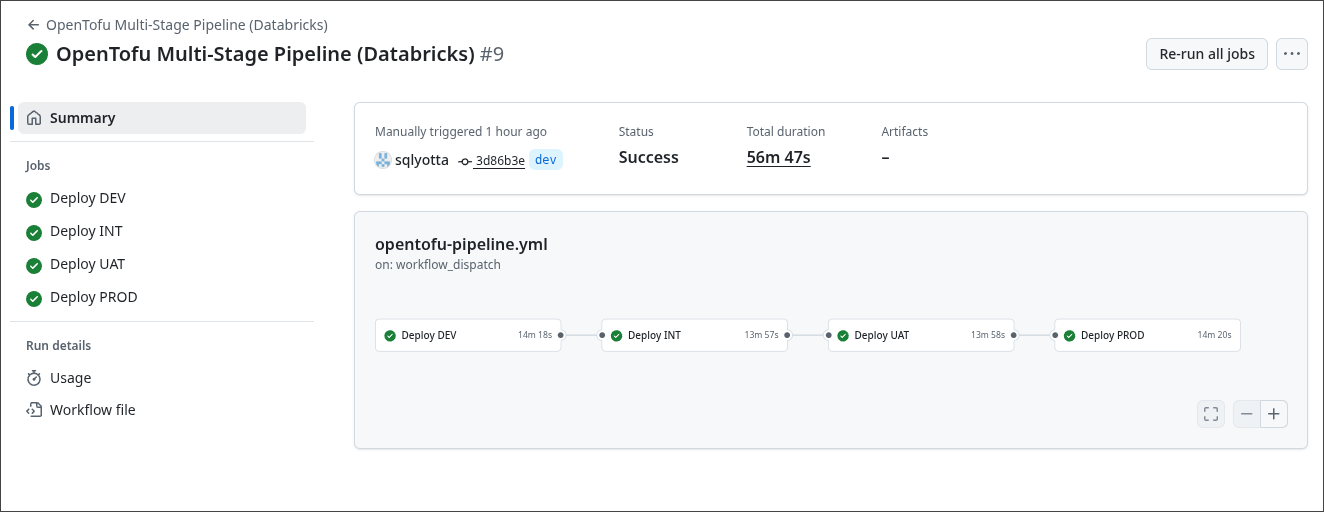
Nous avons bien entendu accès aux logs du workflow, ce qui permet de suivre en temps réel chaque étape du déploiement et de diagnostiquer rapidement d’éventuelles erreurs.
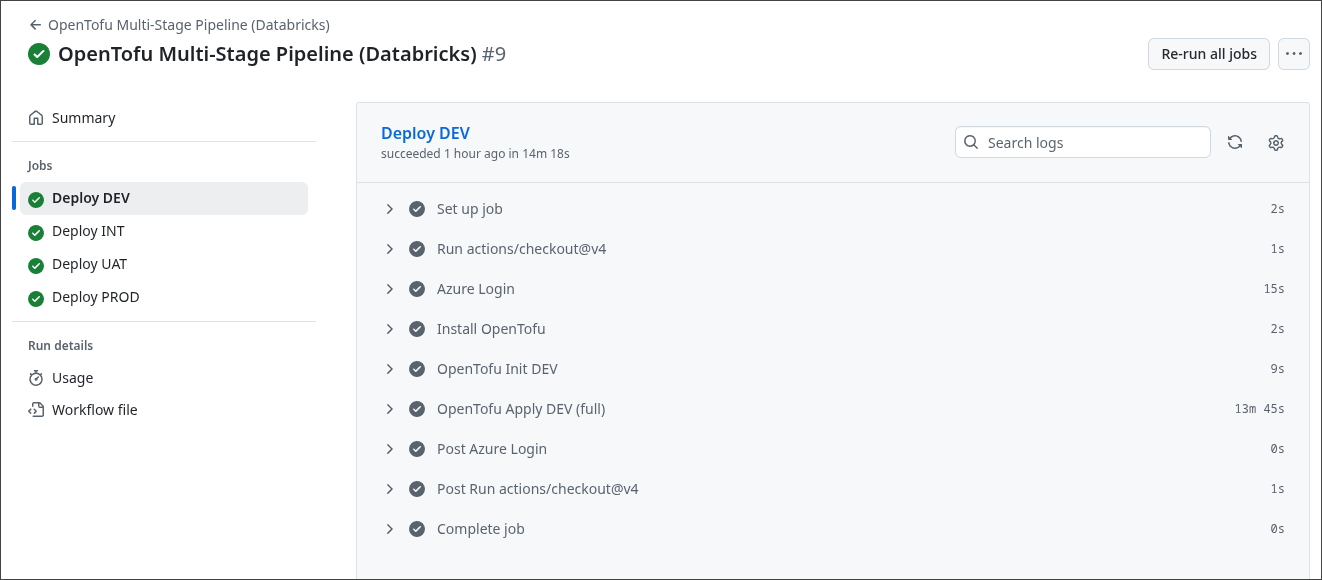
Dans Azure, les ressources sont correctement créées, comme illustré ci-dessous.
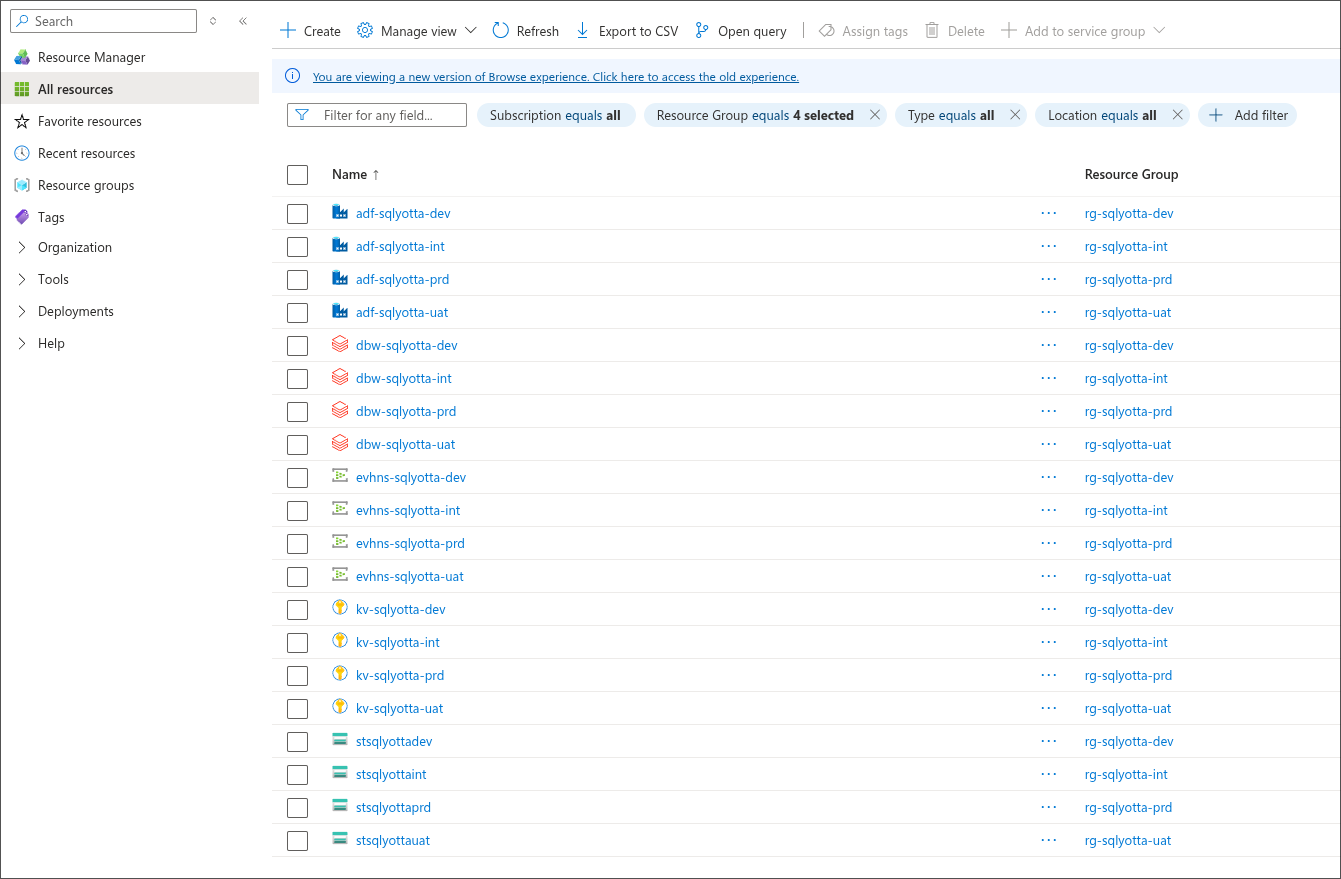
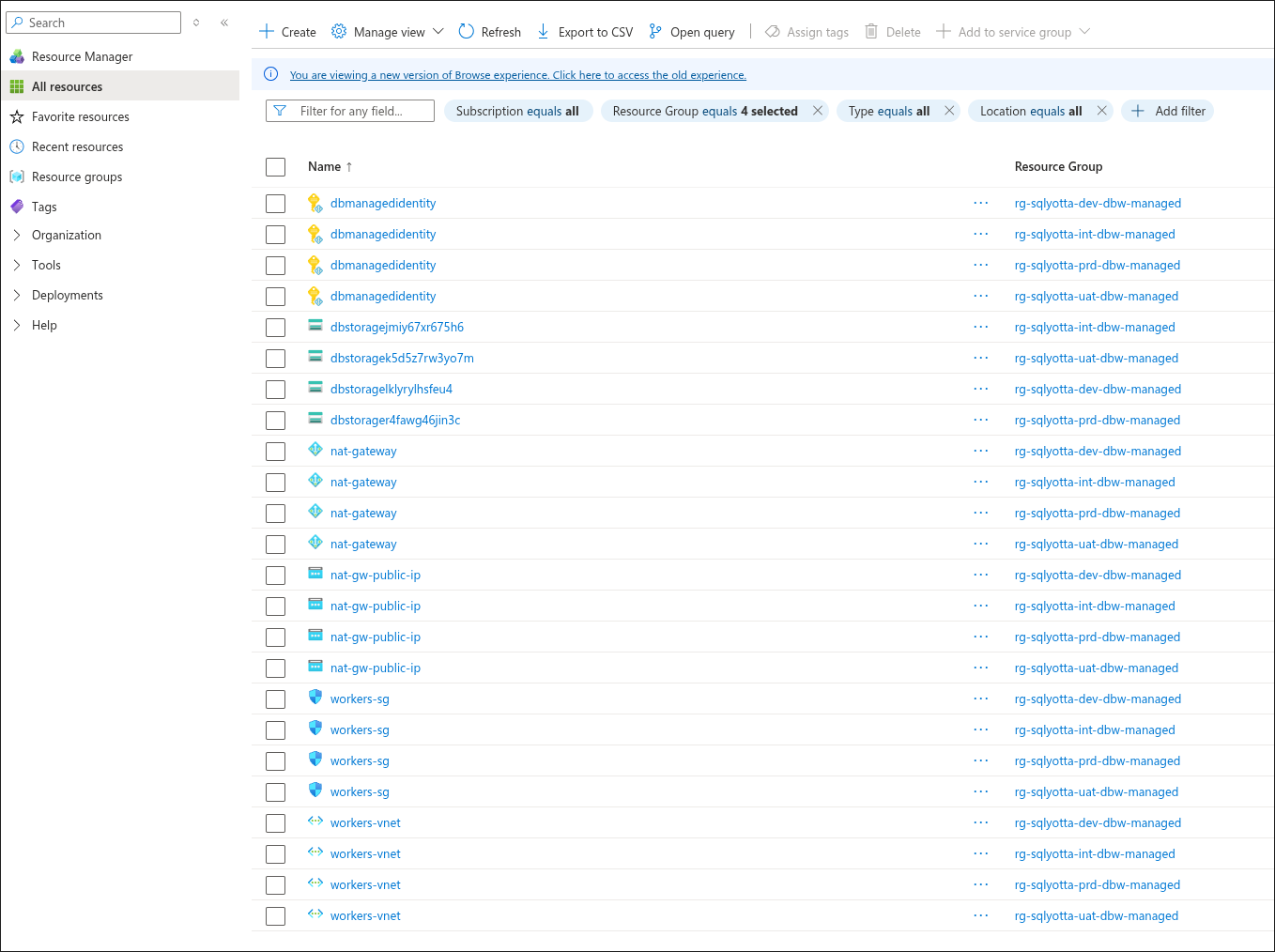
Comme nous déployons des workspaces Databricks, les Resource Groups managés associés sont également créés automatiquement.
Déstruction d'un environnement
Pour supprimer un environnement, il suffit de lancer le workflow de destruction dédié dans GitHub Actions. Après sélection de l’environnement ciblé (dev, int, uat ou prd), le pipeline s’authentifie via OIDC, initialise le backend correspondant puis exécute un tofu destroy avec les variables associées.
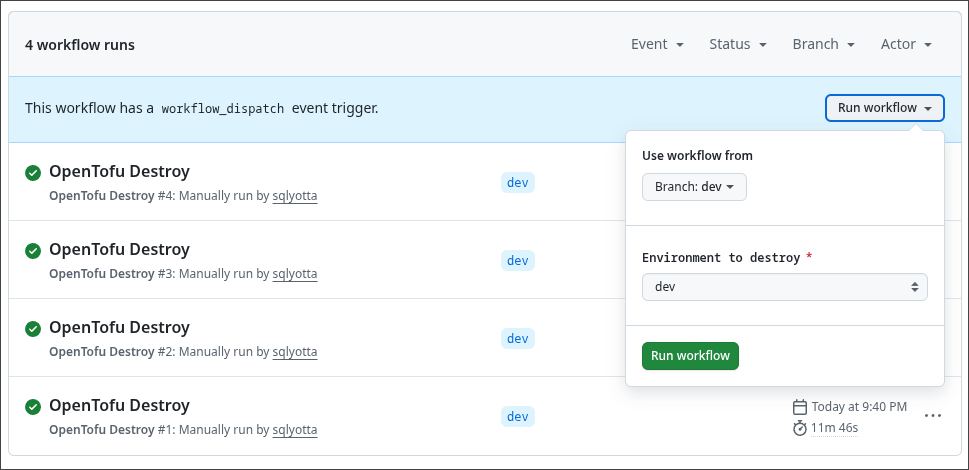
L’ensemble des ressources de l’environnement sont alors retirées proprement, garantissant un cycle complet de création–destruction entièrement automatisé.
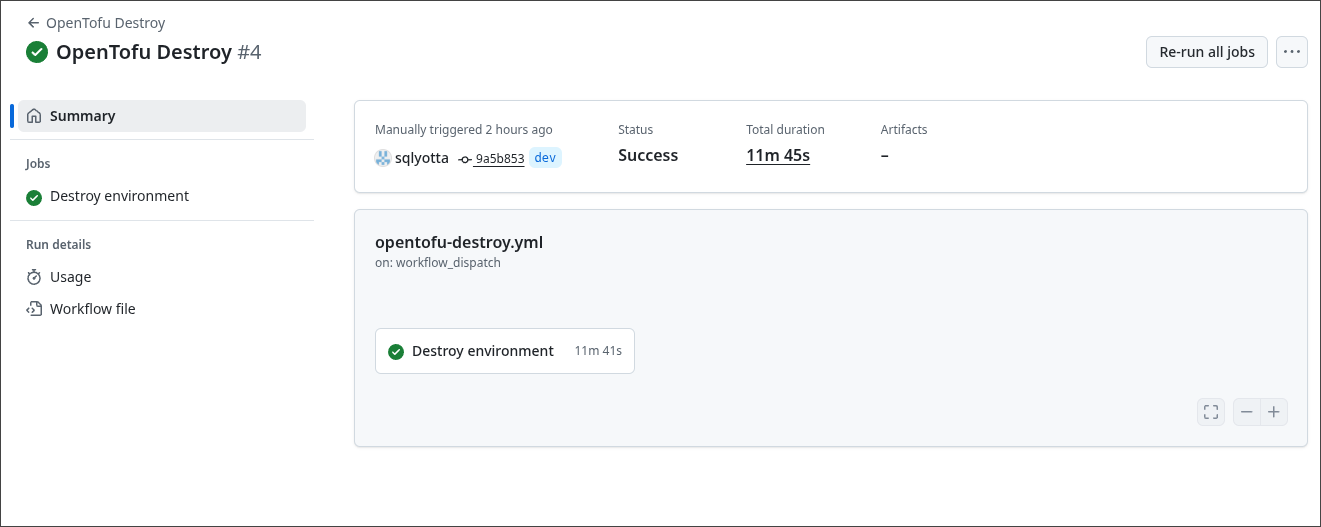
Prochain article, nous parlerons davantage data… et un peu moins infra 😉